Scaling AFL to a 256 thread machine
Changelog
| Date | Info |
|---|---|
| 2018-09-16 | Initial |
| 2018-09-16 | Changed custom JPEG test program a little, saves 2 syscalls bringing us from 9 per fuzz case to 7 fuzz case. Used -O2 flag to build. Neither of these had a noticeable impact on performance thus performance numbers were not updated. |
Performance disclaimer
Performance is critical to my work and I’ve been researching specifically fuzzer performance and scaling for the past 5 years. It’s important that the performance numbers here are accurate and use tooling to their fullest. Please let me know about any suggestions that I could do to make these numbers better while still using unmodified AFL. I also was using a stock libjpeg as I do not want to make internal mods to JPEG as that increases risk of invalid results.
The machine this testing was done on is a single socket Intel Xeon Phi 7210 a 64-core 256-thread machine (yes, 4 HW threads per core). This is clocked at 1.3 GHz and the cores are effectively Atom cores, making the much weaker than conventional ones. A single 1.3 GHz Phi core here usually runs identical code about 10-20x slower than a conventional modern Xeon at 2.8 GHz. This means that numbers here might seem unreasonably low compared to what you may expect, but it’s because these are weak cores.
Intro
I’ve been trying to get AFL to scale correctly for the past day, which turns out to be fairly hard. AFL doesn’t really provide any built in way of just spinning up multiple cores by using something like afl-fuzz -j64 ..., so we have to do it ourselves. Further the machine I’m trying this on is quite exotic and not much scales correctly to it anyways. But, let’s hop right on in and give it a go! This testing is actually being done for an upcoming blog series demonstrating a neat new way of fuzzing and harnessing that I call “Vectorized Emulation”. I wanted to get the best performance numbers out of AFL so I had a reasonable comparison that would make some of the tech a bit more relatable. Stay tuned for that post hopefully within a week!
In this blog I’m going to talk about the major things to keep an eye on when you’re trying to get every drop of performance:
- Are you using all your cores?
- Are you scaling well?
- Are you spending time in your actual target or other things like the kernel?
If you’re just spinning up one process per core, it’s very possible that all of these are not true. We’ll go through a real example of this process and how easy it is to fall into a trap of not effectively using your cores.
Target selection
First of all, we need a good target that we can try to fuzz as fast as possible. Something that is common, reasonably small, and easy to convert to use AFL persistent mode. I’ve decided to look at libjpeg-turbo as it’s a common target, many people are probably already familiar, and it’s quite simple to just throw in a loop. Further if we found a bug it’d be a pretty good day, so it’s always fun to play with real targets.
Fuzzing out of the can
The first thing I’m going to try on almost any new target I look at will be to find a tool that already comes with the source that in some way parses the image. In this case for libjpeg-turbo we can actually use the tool that comes with called djpeg. This is a simple command line utility that takes in a file over stdin or via a command line argument, and produces another output file potentially of another format. Since we know we are going to use AFL, let’s get a basic AFL environment set up. It’s pretty simple, and in our case we’re using afl-2.52b the latest at the time of writing this blog. We’re not using ASAN as we’re looking for best case performance numbers.
pleb@debphi:~/blogging$ wget http://lcamtuf.coredump.cx/afl/releases/afl-latest.tgz
--2018-09-16 16:09:11-- http://lcamtuf.coredump.cx/afl/releases/afl-latest.tgz
Resolving lcamtuf.coredump.cx (lcamtuf.coredump.cx)... 199.58.85.40
Connecting to lcamtuf.coredump.cx (lcamtuf.coredump.cx)|199.58.85.40|:80... connected.
HTTP request sent, awaiting response... 200 OK
Length: 835907 (816K) [application/x-gzip]
Saving to: ‘afl-latest.tgz’
afl-latest.tgz 100%[========================================================================================================================================>] 816.32K 323KB/s in 2.5s
2018-09-16 16:09:14 (323 KB/s) - ‘afl-latest.tgz’ saved [835907/835907]
pleb@debphi:~/blogging$ tar xf afl-latest.tgz
pleb@debphi:~/blogging$ cd afl-2.52b/
pleb@debphi:~/blogging/afl-2.52b$ make -j256
[*] Checking for the ability to compile x86 code...
[+] Everything seems to be working, ready to compile.
cc -O3 -funroll-loops -Wall -D_FORTIFY_SOURCE=2 -g -Wno-pointer-sign -DAFL_PATH=\"/usr/local/lib/afl\" -DDOC_PATH=\"/usr/local/share/doc/afl\" -DBIN_PATH=\"/usr/local/bin\" afl-gcc.c -o afl-gcc -ldl
set -e; for i in afl-g++ afl-clang afl-clang++; do ln -sf afl-gcc $i; done
cc -O3 -funroll-loops -Wall -D_FORTIFY_SOURCE=2 -g -Wno-pointer-sign -DAFL_PATH=\"/usr/local/lib/afl\" -DDOC_PATH=\"/usr/local/share/doc/afl\" -DBIN_PATH=\"/usr/local/bin\" afl-fuzz.c -o afl-fuzz -ldl
cc -O3 -funroll-loops -Wall -D_FORTIFY_SOURCE=2 -g -Wno-pointer-sign -DAFL_PATH=\"/usr/local/lib/afl\" -DDOC_PATH=\"/usr/local/share/doc/afl\" -DBIN_PATH=\"/usr/local/bin\" afl-showmap.c -o afl-showmap -ldl
cc -O3 -funroll-loops -Wall -D_FORTIFY_SOURCE=2 -g -Wno-pointer-sign -DAFL_PATH=\"/usr/local/lib/afl\" -DDOC_PATH=\"/usr/local/share/doc/afl\" -DBIN_PATH=\"/usr/local/bin\" afl-tmin.c -o afl-tmin -ldl
cc -O3 -funroll-loops -Wall -D_FORTIFY_SOURCE=2 -g -Wno-pointer-sign -DAFL_PATH=\"/usr/local/lib/afl\" -DDOC_PATH=\"/usr/local/share/doc/afl\" -DBIN_PATH=\"/usr/local/bin\" afl-gotcpu.c -o afl-gotcpu -ldl
cc -O3 -funroll-loops -Wall -D_FORTIFY_SOURCE=2 -g -Wno-pointer-sign -DAFL_PATH=\"/usr/local/lib/afl\" -DDOC_PATH=\"/usr/local/share/doc/afl\" -DBIN_PATH=\"/usr/local/bin\" afl-analyze.c -o afl-analyze -ldl
cc -O3 -funroll-loops -Wall -D_FORTIFY_SOURCE=2 -g -Wno-pointer-sign -DAFL_PATH=\"/usr/local/lib/afl\" -DDOC_PATH=\"/usr/local/share/doc/afl\" -DBIN_PATH=\"/usr/local/bin\" afl-as.c -o afl-as -ldl
ln -sf afl-as as
[*] Testing the CC wrapper and instrumentation output...
unset AFL_USE_ASAN AFL_USE_MSAN; AFL_QUIET=1 AFL_INST_RATIO=100 AFL_PATH=. ./afl-gcc -O3 -funroll-loops -Wall -D_FORTIFY_SOURCE=2 -g -Wno-pointer-sign -DAFL_PATH=\"/usr/local/lib/afl\" -DDOC_PATH=\"/usr/local/share/doc/afl\" -DBIN_PATH=\"/usr/local/bin\" test-instr.c -o test-instr -ldl
echo 0 | ./afl-showmap -m none -q -o .test-instr0 ./test-instr
echo 1 | ./afl-showmap -m none -q -o .test-instr1 ./test-instr
[+] All right, the instrumentation seems to be working!
[+] LLVM users: see llvm_mode/README.llvm for a faster alternative to afl-gcc.
[+] All done! Be sure to review README - it's pretty short and useful.
Out of the box AFL gives us some compiler wrappers for gcc and clang, afl-gcc and afl-clang respectively. We’ll use these to build the libjpeg-turbo source so AFL adds instrumentation that is used for coverage and feedback. Which is critical to modern fuzzer operation, especially when just doing byte flipping like AFL does.
Let’s grab libjpeg-turbo and build it:
pleb@debphi:~/blogging$ git clone https://github.com/libjpeg-turbo/libjpeg-turbo
Cloning into 'libjpeg-turbo'...
remote: Counting objects: 13559, done.
remote: Compressing objects: 100% (40/40), done.
remote: Total 13559 (delta 14), reused 8 (delta 1), pack-reused 13518
Receiving objects: 100% (13559/13559), 11.67 MiB | 8.72 MiB/s, done.
Resolving deltas: 100% (10090/10090), done.
pleb@debphi:~/blogging$ mkdir buildjpeg
pleb@debphi:~/blogging$ cd buildjpeg/
pleb@debphi:~/blogging/buildjpeg$ export PATH=$PATH:/home/pleb/blogging/afl-2.52b
pleb@debphi:~/blogging/buildjpeg$ cmake -G"Unix Makefiles" -DCMAKE_C_COMPILER=afl-gcc -DCMAKE_C_FLAGS=-m32 /home/pleb/blogging/libjpeg-turbo/
...
pleb@debphi:~/blogging/buildjpeg$ make -j256
...
[100%] Built target tjunittest-static
pleb@debphi:~/blogging/buildjpeg$ ls
cjpeg CMakeFiles CTestTestfile.cmake jconfig.h jpegtran libjpeg.map libjpeg.so.62.3.0 libturbojpeg.so.0 md5 sharedlib tjbench-static tjexampletest wrjpgcom
cjpeg-static cmake_install.cmake djpeg jconfigint.h jpegtran-static libjpeg.so libturbojpeg.a libturbojpeg.so.0.2.0 pkgscripts simd tjbenchtest tjunittest
CMakeCache.txt cmake_uninstall.cmake djpeg-static jcstest libjpeg.a libjpeg.so.62 libturbojpeg.so Makefile rdjpgcom tjbench tjexample tjunittest-static
Woo! We have a libjpeg-turbo built with AFL and instrumented! We now have a ./djpeg which is what we’re going to use to fuzz. We need a test input corpus of JPEGs, however since we’re benchmarking I just picked a single JPEG that is 3.2 KiB in size. We’ll set up AFL and fuzz this with no frills:
pleb@debphi:~/blogging$ mkdir fuzzing
pleb@debphi:~/blogging$ cd fuzzing/
pleb@debphi:~/blogging/fuzzing$ mkdir inputs
... Copy in an input
pleb@debphi:~/blogging/fuzzing$ mkdir outputs
pleb@debphi:~/blogging/fuzzing$ afl-fuzz -h
pleb@debphi:~/blogging/fuzzing$ afl-fuzz -i inputs/ -o outputs/ -- ../buildjpeg/djpeg @@
Now we’re hacking!
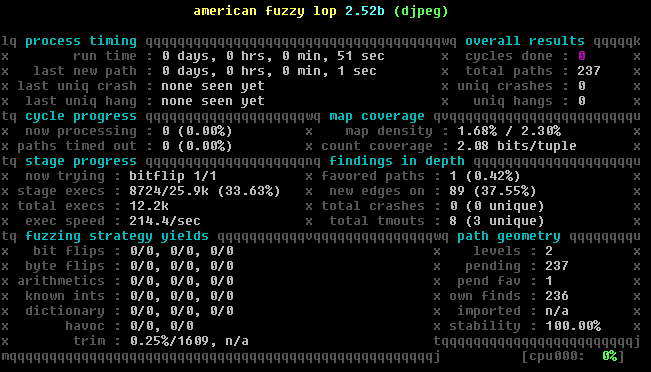
It’s important that you keep an eye on exec speed as it can flutter around during different passes, in this case 210-220 is where it seemed to hover around on average. So I’ll be using the 214.4 number from the picture as the baseline for this first test.
Using all your cores
I’ve got some sad news though. This isn’t using anything but a single core. We have a 256 thread machine and we’re using 1/256th of it to fuzz, what a waste of silicon. Sadly there’s no trivial way to spin up AFL so lets just cheat and grab something that does it for us: afl-launch . This requires go but the instructions are pretty clear on how to get it set up and running. It takes effectively the exact same args as afl-fuzz but it takes an -n parameter that spins up multiple jobs for us. Let’s also switch to a ramdisk to decrease thrashing of the disk (doesn’t matter that much anyways due to FS caching):
pleb@debphi:~/blogging/fuzzing$ rm -rf /mnt/ram/outputs/*
pleb@debphi:~/blogging/fuzzing$ ~/go/bin/afl-launch -n 256 -i /mnt/ram/inputs/ -o /mnt/ram/outputs/ -- ../buildjpeg/djpeg @@
And we expect roughly 214 * 64 (number of exec/sec on single core * number of physical cores) = 14k execs/sec. In reality I expect even more than this due to hyperthreading.
pleb@debphi:~/blogging/fuzzing$ ps a | grep afl-fuzz | grep -v grep | wc -l
256
pleb@debphi:~/blogging/fuzzing$ afl-whatsup -s /mnt/ram/outputs/
status check tool for afl-fuzz by <lcamtuf@google.com>
Summary stats
=============
Fuzzers alive : 256
Total run time : 0 days, 10 hours
Total execs : 0 million
Cumulative speed : 4108 execs/sec
Pending paths : 455 faves, 14932 total
Pending per fuzzer : 1 faves, 58 total (on average)
Crashes found : 0 locally unique
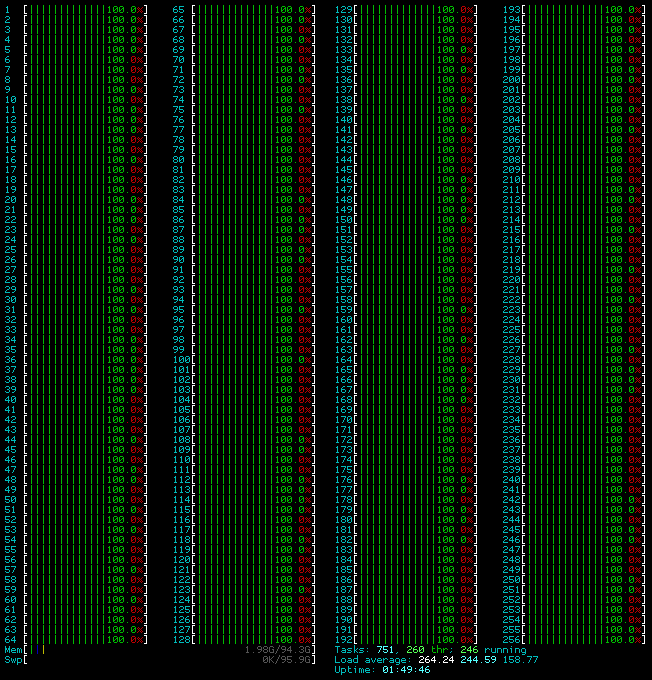
Hmm? What? I’m running 256 instances, afl-whatsup confirms that, but I’m only getting 4.1k execs/sec? That’s a 20x speedup running 256 threads!? Hmm, this is no good. We even switched to a ramdisk so we even have an advantage over the single threaded run. Let’s check out that CPU utilization:

Actually using all your cores
Okay, so apparently we’re only using 22 threads even though we have 256 processes running. Linux will evenly distribute threads so AFL must be doing something special here. If we just look around for affinity in the AFL codebase we stumble across this:
/* Build a list of processes bound to specific cores. Returns -1 if nothing
can be found. Assumes an upper bound of 4k CPUs. */
static void bind_to_free_cpu(void) {
DIR* d;
struct dirent* de;
cpu_set_t c;
u8 cpu_used[4096] = { 0 };
u32 i;
if (cpu_core_count < 2) return;
if (getenv("AFL_NO_AFFINITY")) {
WARNF("Not binding to a CPU core (AFL_NO_AFFINITY set).");
return;
}
d = opendir("/proc");
if (!d) {
WARNF("Unable to access /proc - can't scan for free CPU cores.");
return;
}
ACTF("Checking CPU core loadout...");
/* Introduce some jitter, in case multiple AFL tasks are doing the same
thing at the same time... */
usleep(R(1000) * 250);
/* Scan all /proc/<pid>/status entries, checking for Cpus_allowed_list.
Flag all processes bound to a specific CPU using cpu_used[]. This will
fail for some exotic binding setups, but is likely good enough in almost
all real-world use cases. */
while ((de = readdir(d))) {
u8* fn;
FILE* f;
u8 tmp[MAX_LINE];
u8 has_vmsize = 0;
if (!isdigit(de->d_name[0])) continue;
fn = alloc_printf("/proc/%s/status", de->d_name);
if (!(f = fopen(fn, "r"))) {
ck_free(fn);
continue;
}
while (fgets(tmp, MAX_LINE, f)) {
u32 hval;
/* Processes without VmSize are probably kernel tasks. */
if (!strncmp(tmp, "VmSize:\t", 8)) has_vmsize = 1;
if (!strncmp(tmp, "Cpus_allowed_list:\t", 19) &&
!strchr(tmp, '-') && !strchr(tmp, ',') &&
sscanf(tmp + 19, "%u", &hval) == 1 && hval < sizeof(cpu_used) &&
has_vmsize) {
cpu_used[hval] = 1;
break;
}
}
ck_free(fn);
fclose(f);
}
closedir(d);
for (i = 0; i < cpu_core_count; i++) if (!cpu_used[i]) break;
if (i == cpu_core_count) {
SAYF("\n" cLRD "[-] " cRST
"Uh-oh, looks like all %u CPU cores on your system are allocated to\n"
" other instances of afl-fuzz (or similar CPU-locked tasks). Starting\n"
" another fuzzer on this machine is probably a bad plan, but if you are\n"
" absolutely sure, you can set AFL_NO_AFFINITY and try again.\n",
cpu_core_count);
FATAL("No more free CPU cores");
}
OKF("Found a free CPU core, binding to #%u.", i);
cpu_aff = i;
CPU_ZERO(&c);
CPU_SET(i, &c);
if (sched_setaffinity(0, sizeof(c), &c))
PFATAL("sched_setaffinity failed");
}
#endif /* HAVE_AFFINITY */
We can see that this code does some interesting processing on procfs to find which processors are not in use, and then pins to them. Interestingly we never get the “Uh-oh” message saying we’re out of CPUs, and all 256 of our instances are running. The only way this is possible is if AFL is binding multiple processes to the same core. This is possible due to races on the procfs and the CPU masks not getting updated right away, so some delay has to be added between spinning up AFL instances. But we can do better.
We see at the top of this function this functionality can be turned off entirely by setting the AFL_NO_AFFINITY environment variable. Lets do that and then manage the affinities ourselves. We’re also going to drop the afl-launch tool and just do it ourselves.
import subprocess, threading, time, shutil, os
NUM_CPUS = 256
INPUT_DIR = "/mnt/ram/jpegs"
OUTPUT_DIR = "/mnt/ram/outputs"
def do_work(cpu):
master_arg = "-M"
if cpu != 0:
master_arg = "-S"
# Restart if it dies, which happens on startup a bit
while True:
try:
sp = subprocess.Popen([
"taskset", "-c", "%d" % cpu,
"afl-fuzz", "-i", INPUT_DIR, "-o", OUTPUT_DIR,
master_arg, "fuzzer%d" % cpu, "--",
"../buildjpeg/djpeg", "@@"],
stdout=subprocess.PIPE, stderr=subprocess.PIPE)
sp.wait()
except:
pass
print("CPU %d afl-fuzz instance died" % cpu)
# Some backoff if we fail to run
time.sleep(1.0)
assert os.path.exists(INPUT_DIR), "Invalid input directory"
if os.path.exists(OUTPUT_DIR):
print("Deleting old output directory")
shutil.rmtree(OUTPUT_DIR)
print("Creating output directory")
os.mkdir(OUTPUT_DIR)
# Disable AFL affinity as we do it better
os.environ["AFL_NO_AFFINITY"] = "1"
for cpu in range(0, NUM_CPUS):
threading.Timer(0.0, do_work, args=[cpu]).start()
# Let master stabilize first
if cpu == 0:
time.sleep(1.0)
while threading.active_count() > 1:
time.sleep(5.0)
try:
subprocess.check_call(["afl-whatsup", "-s", OUTPUT_DIR])
except:
pass
By using taskset when we spawn AFL processes we manually control the core rather than AFL trying to figure out what is not being used as we know what’s not used since we’re launching everything. Further we os.environ["AFL_NO_AFFINITY"] = "1" to make sure AFL doesn’t get control over affinity as we now manage it. We’ve got some other things in here like where we give 1 second of delay after the master instance, we automatically clean up the ouput directory, and call afl-whatsup in a loop. We also restart dead afl-fuzz instances which I’ve observed can happen sometimes when spawning everything at once.
status check tool for afl-fuzz by <lcamtuf@google.com>
Summary stats
=============
Fuzzers alive : 256
Total run time : 1 days, 0 hours
Total execs : 6 million
Cumulative speed : 18363 execs/sec
Pending paths : 1 faves, 112903 total
Pending per fuzzer : 0 faves, 441 total (on average)
Crashes found : 0 locally unique

Well that gave us a 4.5x speedup! Look at that CPU utilization!
Optimizing our target for maxium CPU time
We’re now using 100% of all cores. If you’re no htop master you might not know that the red means kernel time on the bars. This means that (eyeballing it) we’re spending about 50% of the CPU time in the kernel. Any time in the kernel is time not spent fuzzing JPEGs. At this point we’ve got AFL doing everything it can, but we’re gonna have to get more creative with our target.
So this is telling us we must be able to find at least a 2x speedup on this target, moving our goal to 40k execs/sec. It’s possible kernel usage is unavoidable, but for something like libjpeg-turbo it would be unreasonable to spend any large amount of time in the kernel anyways. Let’s use everything AFL gives us by using afl persistent mode. This effectively allows you to run multiple fuzz cases in a single instance of the program rather than reverting program state back every fuzz case via clone() or fork(). This can reduce that kernel overhead we’re worried about.
Let’s set up the persistent mode environment by building afl-clang-fast.
pleb@debphi:~/blogging$ cd afl-2.52b/llvm_mode/
pleb@debphi:~/blogging/afl-2.52b/llvm_mode$ make -j8
[*] Checking for working 'llvm-config'...
[*] Checking for working 'clang'...
[*] Checking for '../afl-showmap'...
[+] All set and ready to build.
clang -O3 -funroll-loops -Wall -D_FORTIFY_SOURCE=2 -g -Wno-pointer-sign -DAFL_PATH=\"/usr/local/lib/afl\" -DBIN_PATH=\"/usr/local/bin\" -DVERSION=\"2.52b\" afl-clang-fast.c -o ../afl-clang-fast
ln -sf afl-clang-fast ../afl-clang-fast++
clang++ `llvm-config --cxxflags` -fno-rtti -fpic -O3 -funroll-loops -Wall -D_FORTIFY_SOURCE=2 -g -Wno-pointer-sign -DVERSION=\"2.52b\" -Wno-variadic-macros -shared afl-llvm-pass.so.cc -o ../afl-llvm-pass.so `llvm-config --ldflags`
warning: unknown warning option '-Wno-maybe-uninitialized'; did you mean '-Wno-uninitialized'? [-Wunknown-warning-option]
1 warning generated.
clang -O3 -funroll-loops -Wall -D_FORTIFY_SOURCE=2 -g -Wno-pointer-sign -DAFL_PATH=\"/usr/local/lib/afl\" -DBIN_PATH=\"/usr/local/bin\" -DVERSION=\"2.52b\" -fPIC -c afl-llvm-rt.o.c -o ../afl-llvm-rt.o
[*] Building 32-bit variant of the runtime (-m32)... success!
[*] Building 64-bit variant of the runtime (-m64)... success!
[*] Testing the CC wrapper and instrumentation output...
unset AFL_USE_ASAN AFL_USE_MSAN AFL_INST_RATIO; AFL_QUIET=1 AFL_PATH=. AFL_CC=clang ../afl-clang-fast -O3 -funroll-loops -Wall -D_FORTIFY_SOURCE=2 -g -Wno-pointer-sign -DAFL_PATH=\"/usr/local/lib/afl\" -DBIN_PATH=\"/usr/local/bin\" -DVERSION=\"2.52b\" ../test-instr.c -o test-instr
echo 0 | ../afl-showmap -m none -q -o .test-instr0 ./test-instr
echo 1 | ../afl-showmap -m none -q -o .test-instr1 ./test-instr
[+] All right, the instrumentation seems to be working!
[+] All done! You can now use '../afl-clang-fast' to compile programs.
Now we have an afl-clang-fast binary in the afl-2.52b folder. Let’s rebuild libjpeg-turbo using this
pleb@debphi:~/blogging/buildjpeg$ cmake -G"Unix Makefiles" -DCMAKE_C_COMPILER=afl-clang-fast -DCMAKE_C_FLAGS=-m32 /home/pleb/blogging/libjpeg-turbo/
pleb@debphi:~/blogging/buildjpeg$ make -j256
...
[100%] Built target jpegtran-static
afl-clang-fast 2.52b by <lszekeres@google.com>
[100%] Built target jpegtran
So, libjpeg-turbo is a library. Meaning it’s designed to be used from other programs. It’s also one of the most popular libraries for image compression, so surely it’s relatively easy to use. Let’s quickly write up a bare-bones application that loads an image from a provided argument:
#include <stdlib.h>
#include <stdio.h>
#include <unistd.h>
#include <fcntl.h>
#include "jpeglib.h"
#include <setjmp.h>
struct my_error_mgr {
struct jpeg_error_mgr pub; /* "public" fields */
jmp_buf setjmp_buffer; /* for return to caller */
};
typedef struct my_error_mgr * my_error_ptr;
// Longjmp out on errors
METHODDEF(void)
my_error_exit(j_common_ptr cinfo)
{
my_error_ptr myerr = (my_error_ptr) cinfo->err;
longjmp(myerr->setjmp_buffer, 1);
}
// Eat warnings
METHODDEF(void)
emit_message(j_common_ptr cinfo, int msg_level) {}
GLOBAL(int)
read_JPEG_file (char * filename, unsigned char *filebuf, size_t filebuflen)
{
struct jpeg_decompress_struct cinfo;
struct my_error_mgr jerr;
JSAMPARRAY buffer; /* Output row buffer */
int row_stride; /* physical row width in output buffer */
int fd;
ssize_t flen;
fd = open(filename, O_RDONLY);
if(fd == -1){
return 0;
}
flen = read(fd, (void*)filebuf, filebuflen);
close(fd);
if(flen <= 0){
return 0;
}
cinfo.err = jpeg_std_error(&jerr.pub);
jerr.pub.error_exit = my_error_exit;
jerr.pub.emit_message = emit_message;
/* Establish the setjmp return context for my_error_exit to use. */
if (setjmp(jerr.setjmp_buffer)) {
jpeg_destroy_decompress(&cinfo);
return 0;
}
jpeg_create_decompress(&cinfo);
jpeg_mem_src(&cinfo, filebuf, flen);
(void) jpeg_read_header(&cinfo, TRUE);
(void) jpeg_start_decompress(&cinfo);
row_stride = cinfo.output_width * cinfo.output_components;
buffer = (*cinfo.mem->alloc_sarray)
((j_common_ptr) &cinfo, JPOOL_IMAGE, row_stride, 1);
while (cinfo.output_scanline < cinfo.output_height) {
(void) jpeg_read_scanlines(&cinfo, buffer, 1);
}
(void) jpeg_finish_decompress(&cinfo);
jpeg_destroy_decompress(&cinfo);
return 1;
}
int main(int argc, char *argv[]) {
void *filebuf = NULL;
const size_t filebuflen = 32 * 1024;
if(argc != 2) { fprintf(stderr, "Nice usage noob\n"); return -1; }
filebuf = malloc(filebuflen);
if(!filebuf) {
return -1;
}
while(__AFL_LOOP(100000)) {
read_JPEG_file(argv[1], filebuf, filebuflen);
}
}
This can be built with:
AFL_PATH=/home/pleb/blogging/afl-2.52b afl-clang-fast -O2 -m32 example.c -I/home/pleb/blogging/buildjpeg -I/home/pleb/blogging/libjpeg-turbo /home/pleb/blogging/buildjpeg/libjpeg.a
You can see the code this was derived from with more comments here which I modified to my specific needs and removed almost all comments to keep code as small as possible. It’s also relatively simple to read based off function names.
We made a few changes to the code. We removed all output from the code. It should not print to the screen for warnings or errors, it should not save any files, it should only parse the input. It then will correctly return up via setjmp()/longjmp() on errors and allow us to quickly move to the next case.
You can see we introduced __AFL_LOOP here. This is a special meaning to running this code but only under afl-fuzz. When running it uses signals to notify that it is done with a fuzz case and needs a new one. This loop we set at a limit of 100,000 iterations before tearing down the child and restarting. It’s pretty simple and pretty clean. So now hopefully our syscall usage is down. Let’s check that first.
We’re going to run this new single threaded and verify it’s running as persistent:
pleb@debphi:~/blogging/jpeg_fuzz$ afl-fuzz -i /mnt/ram/jpegs/ -o /mnt/ram/outputs/ -- ./a.out @@
...
[+] Persistent mode binary detected. <<< WOO!
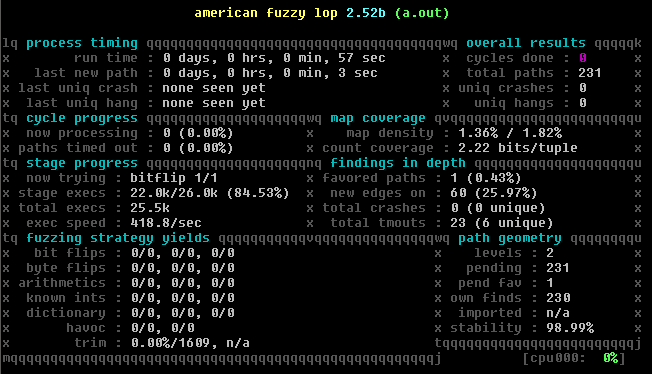
Woo, it’s just a little under 2x faster than the initial single threaded djpeg (we’re running this one ramdisk, but I verified that was not relevant here). It’s just running faster because we’re doing less misc things in the kernel and the code itself.
So AFL tells us that it is persistent, but let’s triple check by running strace on the fuzz process:
ps aux | grep "R.*a.out" | grep -v grep | awk '{print "-p " $2}' | xargs strace
It’s a bit ugly but we strace any actively running a.out task, since it’s crude it might take a few tries to get attached to the right one but I’m no bash pro.
We can see we get a repeating pattern:
openat(AT_FDCWD, "/mnt/ram/outputs//.cur_input", O_RDONLY) = 3
read(3, "\377\330\377\340\0\20JFIF\0\1\1\0\0\1\0\1\0\0\377\333\0C\0\5\3\4\4\4\3\5"..., 32768) = 3251
close(3) = 0
rt_sigprocmask(SIG_BLOCK, ~[RTMIN RT_1], [], 8) = 0
getpid() = 53786
gettid() = 53786
tgkill(53786, 53786, SIGSTOP) = 0
--- SIGSTOP {si_signo=SIGSTOP, si_code=SI_TKILL, si_pid=53786, si_uid=1000} ---
--- stopped by SIGSTOP ---
rt_sigprocmask(SIG_SETMASK, [], NULL, 8) = 0
--- SIGCONT {si_signo=SIGCONT, si_code=SI_USER, si_pid=53776, si_uid=1000} ---
openat(AT_FDCWD, "/mnt/ram/outputs//.cur_input", O_RDONLY) = 3
read(3, "\377\330\377\340\0\20JFIF\0\1\1\0\0\1\0\1\0\0\377\333\0C\0\5\3\4\4\4\3\5"..., 32768) = 3251
close(3) = 0
rt_sigprocmask(SIG_BLOCK, ~[RTMIN RT_1], [], 8) = 0
getpid() = 53786
gettid() = 53786
tgkill(53786, 53786, SIGSTOP) = 0
--- SIGSTOP {si_signo=SIGSTOP, si_code=SI_TKILL, si_pid=53786, si_uid=1000} ---
--- stopped by SIGSTOP ---
rt_sigprocmask(SIG_SETMASK, [], NULL, 8) = 0
--- SIGCONT {si_signo=SIGCONT, si_code=SI_USER, si_pid=53776, si_uid=1000} ---
We see the openat to open, read to read the file, and close when it’s done parsing. So what is the rt_sigprocmask() and beyond? Well in persistent mode AFL uses this to communicate when fuzz cases are done. You can actually find this code in afl-2.52b/llvm_mode/afl-llvm-rt.o.c. There’s a descriptive comment:
/* In persistent mode, the child stops itself with SIGSTOP to indicate
a successful run. In this case, we want to wake it up without forking
again. */
This means that the rt_sigprocmask() and beyond is out of our control. But other than that we’re doing the bare minimum to read a file by doing open, read, and close. Nothing else. We’re running tens of thousands of fuzz cases in a single instance of this program without having to exit() out and fork()!
Alright! Let’s put it all together and fuzz with this new binary on all cores!
status check tool for afl-fuzz by <lcamtuf@google.com>
Summary stats
=============
Fuzzers alive : 256
Total run time : 1 days, 1 hours
Total execs : 20 million
Cumulative speed : 56003 execs/sec
Pending paths : 1 faves, 122669 total
Pending per fuzzer : 0 faves, 479 total (on average)
Crashes found : 0 locally unique
Woo 56k per second! More than the 2x we were expecting from the custom written target. And I’ll save you another htop image and just tell you that now only about 8% of CPU time is spent in the kernel. Given we’re doing 7 syscalls per fuzz case, that means we’re doing about 400k per second, which still is fairly high but most of the syscalls are due to AFL and not us so they’re out of our control.
Conclusion
It’s pretty easy to get stuck thinking tools work out of the box. People usually worry about scaling at the level of “if it’s possible” rather than “is it actually doing more work”. It’s important to note that it’s very easy to run 64 instances of a tool and end up getting very little performance gain. In the world of fuzzing you usually should be able to scale linearly with cores, so if you’re only getting 1/2 efficiency it’s probably time to settle in and figure out if it’s in your control or not.
We were able to go from naive single-core AFL usage with 214 execs/sec, to “just run 256 AFLs” at 4k/sec, to doing some optimizations to get us to 56k/sec. All within a few hours of work. It’d be a shame if we would have just taken the 4k/sec and run with it, as we would be wasting almost all of our CPU.
Extra
This is my first blog, so please let me know anything you want more or less of. Follow me at @gamozolabs on Twitter if you want notifications when new blogs come up, or I think you can use RSS or something if you’re still one of those people.
Shoutouts
Shoutouts to @ScottyBauer1 and @marcograss on Twitter for giving me AFL tips and tricks for getting these numbers up